
本文来自网络多处Python短代码
你必须掌握的20个Python代码,短小精悍,用处无穷
from https://zhuanlan.zhihu.com/p/370071156 by 囍歡
当今python编程语言的潮流已经成为不可阻挡的趋势,python以其较高的可读性和简洁性备受程序员的喜爱。而python编程中的一些小的技巧,运用的恰当,会让你的程序事半功倍。
以下的20个小的程序段,看似非常的简单,但是却非常的有技巧性,并且对个人的编程能力是一个很好的检验,大家应该在日常的编程中多多使用,多多练习。
1.字符串的翻转
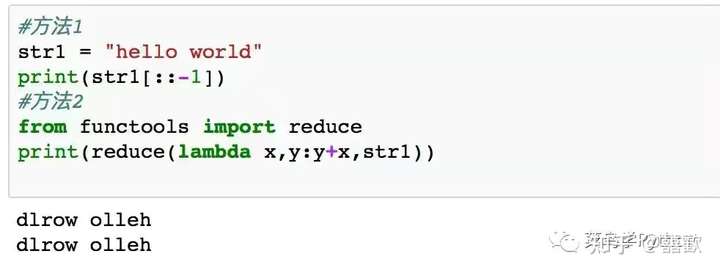
字符串的翻转,首先最简单的方法就是利用切片的操作,来实现翻转,其次可以利用reduce函数来实现翻转,在python3中,reduce函数需要从functools中进行导入。
2.判断字符串是否是回文

该例也可以看作是第一例的应用,利用字符串的翻转来判断字符是否是回文字符串。
3.单词大小写

面对一个字符串,想将里面的单词首字母大写,只需要调用title()函数,而所有的字母大写只需要调用upper()函数,字符串首字母大写则是调用capitalize()函数即可。
4.字符串的拆分

字符串的拆分可以直接利用split函数,进行实现,返回的是列表,而strip函数用于移除字符串头尾指定的字符(默认为空格或换行符)。
5.将列表中的字符串合并

这一条可以认为是第4条的反例,这里是将列表中的字符串合并为字符串。第4条可以与第5条结合,来去除字符串中不想留下的项。
6.寻找字符串中唯一的元素
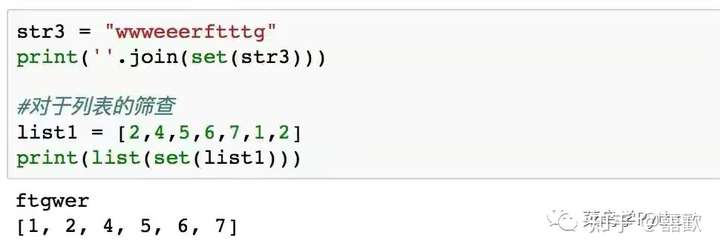
在python中,对于唯一值的筛查,首先应该想到对于set的利用,set可以帮助我们快速的筛查重复的元素,上述程序中,set不仅可以对字符串,而且还可以针对列表进行筛查。
7.将元素进行重复
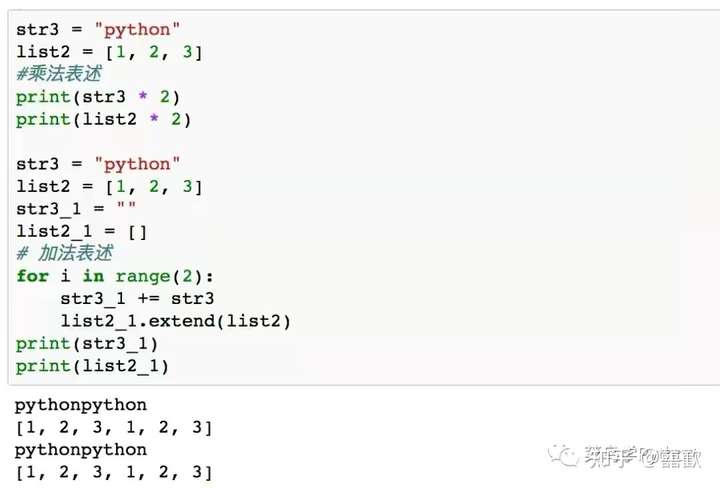
将元素进行重复,可以采用“乘法”的形势,直接乘以原来的元素,也可以采用“加法”的形式,更方便理解。
8.基于列表的扩展

基于列表的扩展,可以充分利用列表的特性和python语法的简洁性,来产生新的列表,或者将嵌套的列表进行展开。
9. 将列表展开
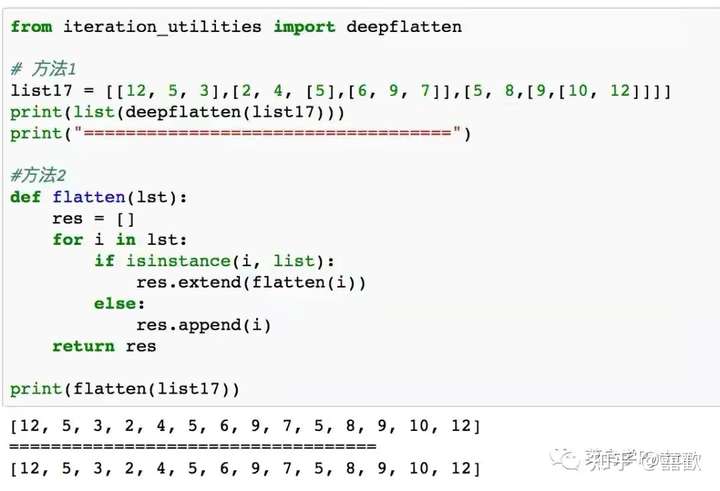
首先,方法1中 ,我们调用的是iteration_utilities 中的deepflatten函数,第二种方法直接采用递归的方法,我们自己来实现复杂列表的展平,便可以得到展开后的列表。
10.二值交换

Python中的二值交换,可以直接采用交换的方式,如上图的方法1,而方法2所示的方法,借助第三个变量,来实现了两个数值的交换。
11.统计列表中元素的频率

我们可以直接调用collections中的Counter类来统计元素的数量,当然也可以自己来实现这样的统计,但是从简洁性来讲,还是以Counter的使用比较方便。
12.判断字符串所含元素是否相同

Counter函数还可以用来判断字符串中包含的元素是否相同,无论字符串中元素顺序如何,只要包含相同的元素和数量,就认为其是相同的。
13.将数字字符串转化为数字列表

上述程序中,方法1利用的map函数,map函数可以将str19中的每个元素都执行int函数,其返回的是一个迭代器,利用list函数来将其转化为列表的形式。注意,在python2中执行map函数就会直接返回列表,而python3做了优化,返回的是迭代器,节省了内存。
14.使用try-except-finally模块
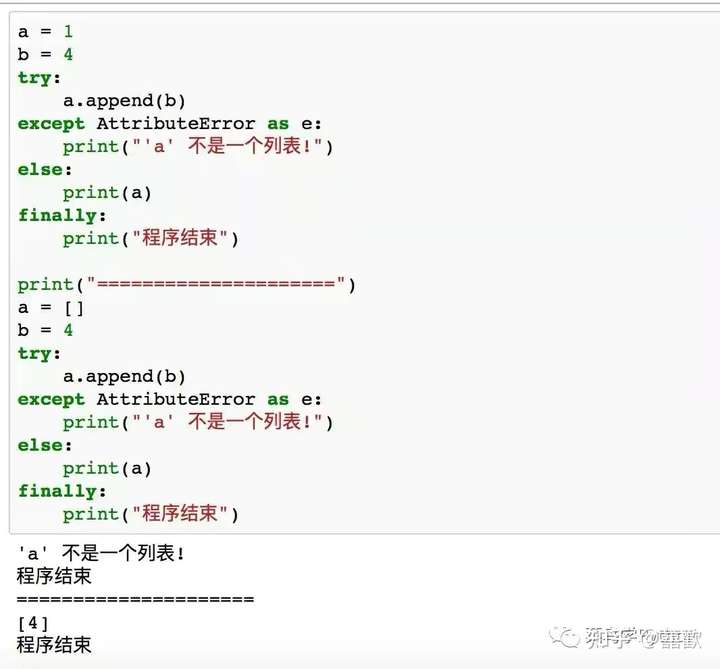
当我们在执行程序时,可能会遇到某些不可预知的错误,使用try-except可以帮助我们去捕获这些错误,然后输出提示。注意,如果需要程序无论是否出错,都要执行一些程序的化,需要利用finally来实现。
15. 使用enumerate() 函数来获取索引-数值对
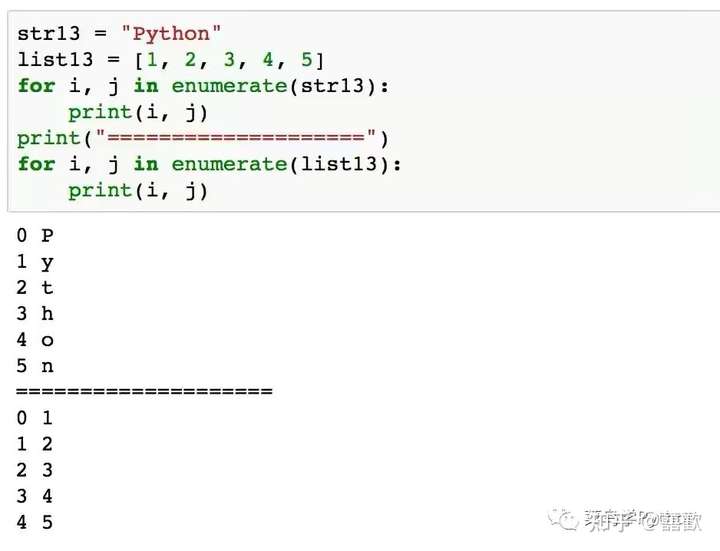
enumerate() 函数用于将一个可遍历的数据对象(如上图的列表,字符串)组合为一个索引序列。
16.代码执行消耗时间
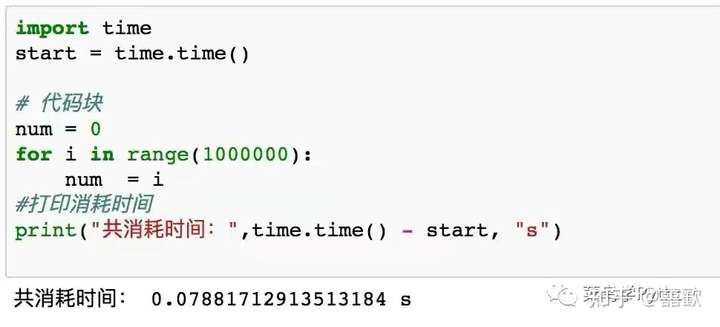
利用time()函数,在核心程序开始前记住当前时间点,然后在程序结束后计算当前时间点和核心程序开始前的时间差,可以帮助我们计算程序执行所消耗的时间。
17.检查对象的内存占用情况

在python中可以使用sys.getsizeof来查看元素所占内存的大小。
18.字典的合并
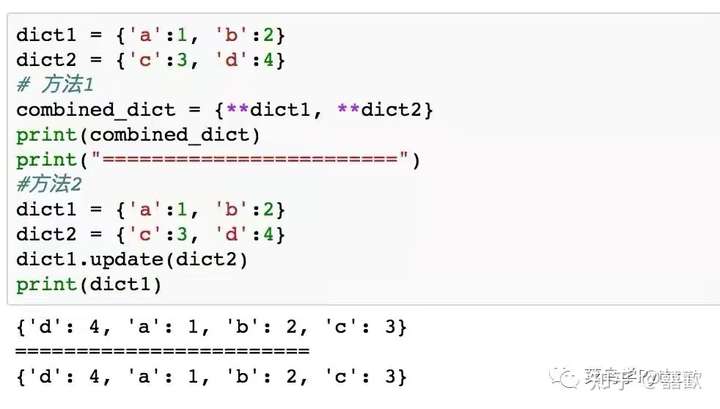
在python3中,提供了新的合并字典的方式,如方法1所示,此外python3还保留了python2的合并字典的方式,如方法2所示。
19.随机采样

使用random.sample()函数,可以从一个序列中选择n_samples个随机且独立的元素。
20.检查唯一性

通过检查列表长度是否与set后的列表长度一致,来判断列表中的元素是否是独一无二的。
8种高级的Python列表使用技巧,代码都给你整理好啦
from https://zhuanlan.zhihu.com/p/383464292 by liustar
这20个短小精悍的小例子还是非常实用的,尤其是对菜鸟来说,多练习一下对功力提升大有裨益!读百遍,看千遍,不然自己动手敲一边。
Python中的列表是我们最常见的数据结构之一,也是最强大的数据结构之一!Python列表功能非常丰富,并且具有很多隐藏的技巧没有被发现。
一、使用Python过滤列表
1.使用Filter()函数
filter()函数采用两个参数:函数和可迭代项。 在这种情况下,我们将定义一个函数并过滤一个列表。
让我们用一个例子来尝试一下!我们将从列表开始,并过滤出所有小于3的项:
original_list = [1,2,3,4,5]
def filter_three(number):
return number > 3
filtered = filter(filter_three, original_list)
filtered_list = list(filtered)
print(filtered_list)
# Returns [4,5]
让我们看看这里发生了什么:
- 我们定义了原始列表
- 然后定义一个接受参数(“ number”)的函数。如果数字大于3,函数将返回True。
- 我们定义了一个应用filter函数的项(“ filtered”)。我们的项已筛选,是筛选对象。
- 最后,我们创建“ filtered_list”,将列表函数替换为filtered对象。
2.具有列表理解
类似地,我们可以用列表理解过滤列表。记住,列表理解是定义和修改列表非常简单快捷的方式。
让我们看看如何通过列表理解来完成前面的任务:
original_list = [1,2,3,4,5]
filtered_list = [number for number in original_list if number > 3]
print(filtered_list)
# Return [4,5]
从这两个示例中我们可以看出,列表理解是一种更简单,更快捷的过滤列表方法。
二、修改列表
1.使用Map()函数
Python Map函数允许我们将函数应用于可迭代对象中的每个项。
假如我们有一个列表,想返回每个数字的平方。我们可以使用map()函数来实现这一点。让我们看一下具体操作:
original_list = [1,2,3,4,5]
def square(number):
return number ** 2
squares = map(square, original_list)
squares_list = list(squares)
print(squares)
# Returns [1, 4, 9, 16, 25]
让我们探讨一下这里发生了什么:
首先,我们定义了原始列表和一个返回其参数平方(“number”)的函数。
然后,我们创建一个名为“squares”的新变量,它是map函数的结果,函数和原始列表作为其参数。
最后,我们创建另一个新变量,将list函数应用于squares变量。
这个方法有点复杂!接下来让我们看看清单理解!
2.具有列表理解
我们可以使用列表理解来修改列表项。这甚至是一个更容易和更优雅的方式来编写我们的代码。
让我们尝试一下!
original_list = [1,2,3,4,5]
squares_list = [number ** 2 for number in original_list]
print(squares_list)
# Returns [1,4,9,16,25]
三、将列表与Zip()函数合并
在某些情况下,可能需要合并两个或多个列表。这就是zip()函数的作用:在每个索引处创建一个包含列表对应元素的对象。
让我们用一个例子来尝试一下:
numbers = [1,2,3]
letters = ['a', 'b', 'c']
combined = zip(numbers, letters)
combined_list = list(combined)
# returns [(1, 'a'), (2, 'b'), (3, 'c')]
四、颠倒列表
Python列表是有序的数据结构。因此,项目的顺序很重要。有时我们可能需要颠倒列表中的项,这可以使用Python切片操作轻松完成。
让我们用一个例子来尝试一下:
original_list = [1,2,3,4,5]
reversed_list = original_list[::-1]
print(reversed_list)
# Returns: [5,4,3,2,1]
五、检查列表中的成员身份
有时我们想查看列表中是否存在某个项。
我们只需使用in运算符即可完成此操作。
games = ['Yankees', 'Yankees', 'Cubs', 'Blue Jays', 'Giants']
def isin(item, list_name):
if item in list_name: print(f"{item} is in the list!")
else: print(f"{item} is not in the list!")
isin('Blue Jays', games)
isin('Angels', games)
# Returns
#Blue Jays在名单上!
#Angels不在名单上!
六、查找列表中最常见的项
如果你想在列表中找到最常见的项。例如,你可能在列表中记录了正反面游戏的获胜者,并且想知道哪个赢得最多。
games = ['heads', 'heads', 'tails', 'heads', 'tails']
items = set(games)
print(max(items, key = games.count))
让我们看看这段代码做什么:
- 我们用五个正面或反面游戏的结果来定义一个列表;
- 我们定义了列表中所有项的集合。set()函数过滤掉了列表中的重复项;
- 最后,我们将max()应用于项目集,并使用key参数作为集合中元素的最高计数。
七、展开列表
有时我们会得到一个列表,其中包含其他列表,也就是表中有表。你可以使用列表理解轻松做到这一点!
让我们尝试一下:
nested_list = [[1,2,3],[4,5,6],[7,8,9]]
flat_list = [i for j in nested_list for i in j]
print(flat_list)
# Returns [1, 2, 3, 4, 5, 6, 7, 8, 9]
八、检查唯一性
如果需要检查列表中的所有项是否唯一,则可以使用集合的功能来完成此操作!
Python中的集合类似于列表(因为它是可变且无序的),但是它只能包含唯一的项。
为此,我们需要使用一个函数将列表转换为一个集合,并比较两个项的长度::
list1 = [1,2,3,4,5]
list2 = [1,1,2,3,4]
def isunique(list):
if len(list) == len(set(list)):
print('Unique!')
else: print('Not Unique!')
isunique(list1)
isunique(list2)
# Returns
# 唯一性
# 不唯一
Python优雅写法,让你工作效率翻2倍
fromhttps://zhuanlan.zhihu.com/p/66488546 by Wayne
我们都知道,Python 的设计哲学是「优雅」、「明确」、「简单」。这也许很多人选择 Python 的原因。但是我收到有些伙伴反馈,他写的 Python 并不优雅,甚至很臃肿,那可能是你的姿势不对哦!今天就给大家带来 Python 语句的十大优雅之法。
为多个变量赋值
有时,有多个变量需要赋值,这时你会怎么赋值呢?
常规方法:
常规方法是给变量逐个赋值。
a = 0
b = 1
c = 2
优雅方法:
直接按顺序对应一一赋值。
a, b, c = 0, 1, 2
序列解包
需要取出列表中的元素。
常规方法:
一般我们知道可以通过下标获取具体元素。
info = ['brucepk', 'man', 'python']
name = info[0]
sex = info[1]
tech = info[2]
print(name,sex,tech)
# 结果
brucepk man python
优雅方法:
给出对应变量接收所有元素。
info = ['brucepk', 'man', 'python']
name,sex,tech = info
print(name,sex,tech)
# 结果
brucepk man python
优雅你的判断语句
我们用判断语句来定义一个绝对值函数。
常规方法:
x = -6
if x < 0:
y = -x
else:
y = x
print(y)
# 结果
6
优雅方法:
x = -6
y = -x if x<0 else x
print(y)
# 结果
6
区间判断
使用 and 连续两次判断的语句,条件都符合时才执行语句。
常规方法:
score = 82
if score >=80 and score < 90:
level = 'B'
print(level)
# 结果
B
优雅方法:
使用链式判断。
score = 82
if 80 <= score < 90:
level = 'B'
print(level)
# 结果
B
多个值符合条件判断
多个值任意一个值符合条件即为 True 的情况。
常规方法:
num = 1
if num == 1 or num == 3 or num == 5:
type = '奇数'
print(type)
# 结果
奇数
优雅方法:
使用关键字 in,让你的语句更优雅。
num = 1
if num in(1,3,5):
type = '奇数'
print(type)
# 结果
奇数
判断是否为空
判断元素是空还是非空。
常规方法:
一般我们想到的是 len() 方法来判断元素长度,大于 0 则为非空。
A,B,C =[1,3,5],{},''
if len(A) > 0:
print('A 为非空')
if len(B) > 0:
print('B 为非空')
if len(C) > 0:
print('C 为非空')
# 结果
A 为非空
优雅方法:
在之前的文章 零基础学 python 之 if 语句 中讲过,if 后面的执行条件是可以简写的,只要条件 是非零数值、非空字符串、非空 list 等,就判断为 True,否则为 False。
A,B,C =[1,3,5],{},''
if A:
print('A 为非空')
if B:
print('B 为非空')
if C:
print('C 为非空')
# 结果
A 为非空
多条件内容判断至少一个成立
常规方法:
用 or 连接多个条件。
math,English,computer =90,80,88
if math<60 or English<60 or computer<60:
print('not pass')
# 结果
not pass
优雅方法:
使用 any 语句。
math,English,computer =90,59,88
if any([math<60,English<60,computer<60]):
print('not pass')
# 结果
not pass
多条件内容判断全部成立
常规方法:
使用 and 连接条件做判断。
math,English,computer =90,80,88
if math>60 and English>60 and computer>60:
print('pass')
# 结果
pass
优雅方法:
使用 all 方法。
math,English,computer =90,80,88
if all([math>60,English>60,computer>60]):
print('pass')
# 结果
pass
遍历序列的元素和元素下标
常规方法:
使用 for 循环进行遍历元素和下标。
L =['math', 'English', 'computer', 'Physics']
for i in range(len(L)):
print(i, ':', L[i])
# 结果
0 : math
1 : English
2 : computer
3 : Physics
优雅方法:
使用 enumerate 函数。
L =['math', 'English', 'computer', 'Physics']
for k,v in enumerate(L):
print(k, ':', v)
# 结果
0 : math
1 : English
2 : computer
3 : Physics
循环语句优化
之前的文章 零基础学 Python 之列表生成式 中讲过列表生成时的用法,举例:生成 [1x1,2x2,3x3,4x4,5x5]。
常规方法:
使用简单的 for 循环可以达到目的。
L = []
for i in range(1, 6):
L.append(i*i)
print(L)
#结果:
[1, 4, 9, 16, 25]
优雅方法:
使用列表生成式,一行代码搞定。
print([x*x for x in range(1, 6)])
#结果:
[1, 4, 9, 16, 25]
Python 这些优雅的写法学会了吗?自己赶紧动手试试吧。
9个实用的Python小技巧,让你编写出更快、更好的脚本!
from https://zhuanlan.zhihu.com/p/380482726
欢迎关注
,专注Python、数据分析、数据挖掘、好玩工具
编写 Python 脚本来解决各种小问题是我每天的乐趣之一。我总是喜欢找出一个问题的 Pythonic 答案,也喜欢当我不知道解决办法时,可以很快地在 stack overflow 查找,并发现一些非常棒的解决方法。
在本文中,我将分享9个 Python 小技巧,这些在日常工作中常常用到,有所收获,点赞支持,欢迎收藏。
1、使用defaultdict和lambda函数创建字典
from collections import defaultdict
import numpy as np
q = defaultdict(lambda: np.zeros(5))
# Example output
In [34]: q[0]
Out[34]: array([0., 0., 0., 0., 0.])
defaultdicts 最酷的一点是,它们永远不会引发 KeyError 。任何不存在的键都会获取默认工厂返回的值,在本例中,默认工厂是一个lambda函数,它为给定的任何键返回一个默认NumPy数组,其中包含5个零。
2、正则表达式基本配方
import re
pattern = re.compile(r”\d\d”)
print(re.search(pattern,"Let's find the number 23").group())
# or
print(re.findall(pattern, “Let's find the number 23”))[0]
# Outputs
'23'
'23'
Regex 对于许多 python 程序员来说都是必须的,所以记住核心Regex方法总是很有帮助的。
3、使用集合从两个列表中获得差异
list1 = [1,2,3,4,5]
list2 = [3,4,5]
print(list(set(list1) — set(list2)))
# or
print(set(lista1).difference(set(lista2)))
# Outputs
[1,2]
{1,2}
在这里,集合有助于获得两个python列表之间的差异,这两个列表既是一个列表,也是一个集合。
4、partial 函数
from functools import partial
def multiply(x,y):
return x*y
dbl = partial(multiply,2)
print(dbl)
print(dbl(4))
# Outputs
functools.partial(<function multiply at 0x7f16be9941f0>, 2)
8
在这里,我们创建一个函数,它复制另一个函数,但使用的参数比原始函数少,这样您就可以使用它将该参数应用于多个不同的参数。
5、使用 hasattr()内置方法获取object属性
class SomeClass:
def __init__(self):
self.attr1 = 10
def attrfunction(self):
print("Attreibute")
hasattr(SomeClass, "attrfunction")
# Output
True
6、使用isinstance()检查变量是否为给定类型
isinstance(1, int)
#Output
True
7、使用map()打印列表中的数字
list1 = [1,2,3]
list(map(print, list1))
# Output
1
2
3
一种比循环打印列表内容更快更有效的方法。
8、使用.join()方法格式化datetime日期
from datetime import datetime
date = datetime.now()
print("-".join([str(date.year), str(date.month), str(date.day)])
# Output
'2021-6-15'
9、将两个具有相同规则的列表随机化
import numpy as np
x = np.arange(100)
y = np.arange(100,200,1)
idx = np.random.choice(np.arange(len(x)), 5, replace=False)
x_sample = x[idx]
y_sample = y[idx]
print(x_sample)
print(y_sample)
# Outputs
array([68, 87, 41, 16, 0])
array([168, 187, 141, 116, 100])
文章推荐
数据缺失影响模型效果?是时候需要missingno工具包来帮你了!
4 款 Python 数据探索性分析(EDA)工具包,总有一款适合你!
整理不易,有所收获,点个赞和爱心❤️,更多精彩欢迎关注

文章评论